
Perceptron
Perceptron
原理
简单的感知机可以看作一个二分类,假定我们的公式为
f(x) = sign(w *x + b)
我们把 -b 做为一个标准,w* x 的结果与 -b 这个标准比较,
w*x > -b, f(x) = +1
w *x < -b, f(x) = -1
不难看出w是超平面的法向量,超平面上的向量与w的数量积为0。因此这个超平面就可以很好的区分我们的数据集。
而感知机就是来寻找w和b
优化方法
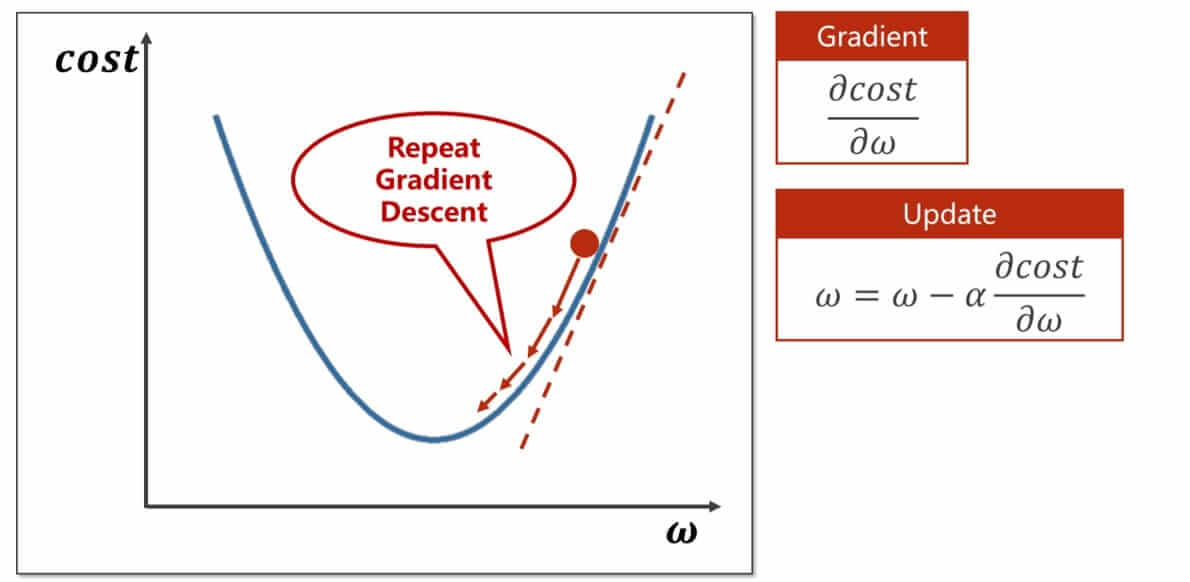
优化方法我们现有的方法比较多,诸如GD、SGD、Minibatch、Adam
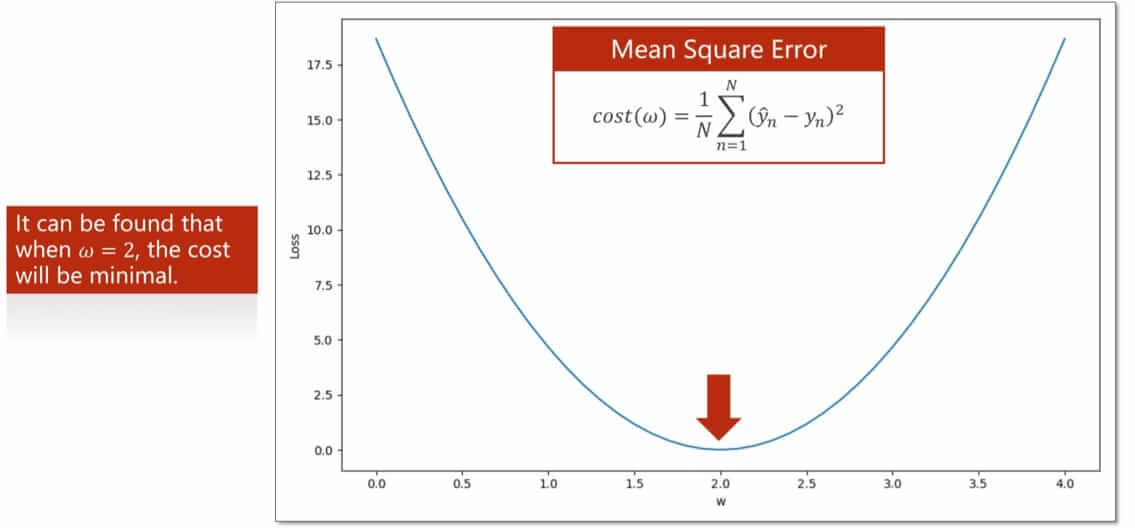
当然我们的损失函数也包含多种,常见的有MSE, CrossEntropy.
这边简单展示一下MSE以及GD原理。
SoftMax
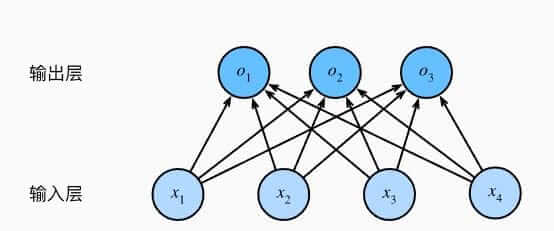
如果我们输出为多分类,那就成为一个SoftMax回归。
SoftMax回归和线性回归一样将输入特征与权重做线性叠加。与线性回归的一个主要不同在于,SoftMax回归的输出值个数等于标签里的类别数。
MLP
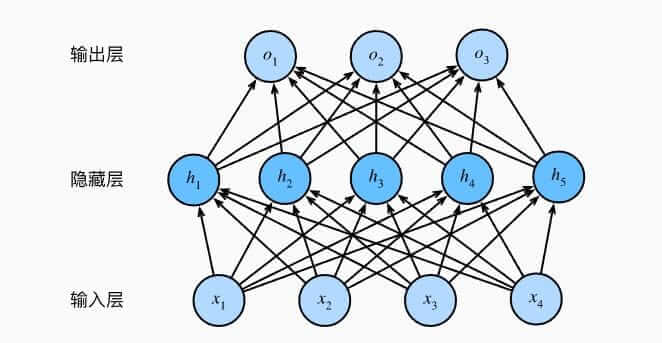
而我们给SoftMax回归增加隐藏层,就是我们所说的多层感知机,而
全连接层只是对数据做仿射变换,我们的方法是引入非线性变换,就是激活函数。
代码实现
这边选用CIFAR10数据集来做演示。CIFAR10包含10个类别,每个类别600张32x32的彩色图像。
1.导入依赖包
1 | import torch |
2.加载数据集
这边对图片进行归一化处理。
1 | transform = transforms.Compose( |
3.定义模型及参数
用Sequential快速构建,对数据进行展平处理输入尺寸为图片尺寸 x 通道数,输出10分类,hidden layer设置为512。
1 | net = nn.Sequential( |
4.训练
损失计算选用交叉熵函数,优化器选用SGD,调用显卡运行。
1 | loss = nn.CrossEntropyLoss() |
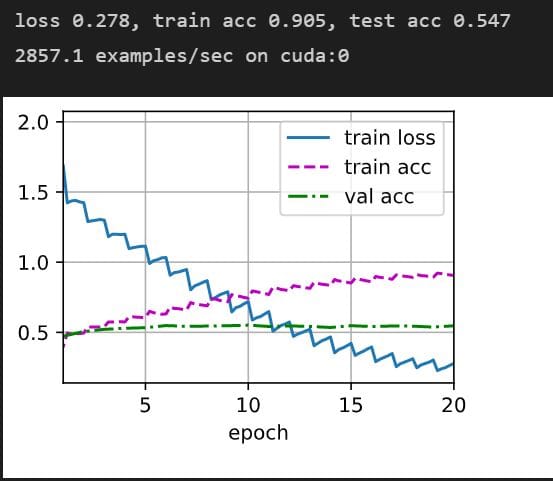
结果
可以看出我们的验证准确值过低,这主要是因为数据集特征不明显,我们在更换数据集验证。
更换数据集
选用7分类的海贼王图片进行训练,可以看出训练结果明显优于CIFAR数据集。
)
同时我们再挑选一张不在训练集的图片进行验证,发现结果正确。
)
相关推荐

2021-11-07
VGG16实现分类任务
VGG16实现分类任务 VGG是2014年由牛津大学著名研究组VGG(Visual Geometry Group)提出,斩获当年ImageNet竞赛中定位任务第一名和分类任务第二名。 原理图 20211107_1 原理简述 例如有张224x224的RGB图片,我们让他通过两个卷积核为3的卷积层,再通过最大池化层(核尺寸为2,步距为2)。至于卷积层的输入输出维度,参考下图,我们一般常用VGG16模型,最终用多个FC实现分类,也可将FC换成卷积核为1的卷积层。 数据集 同样选用本人常用的海贼王数据集来测试,可以根据个人需求修改。 下面提供一个简单数据集。 Kaggle的鸟儿分类数据集,共315个分类 https://www.kaggle.com/gpiosenka/100-bird-species 可以用kaggle命令选择下载 1kaggle datasets download -d...

2021-11-22
AutoEncoder
AutoEncoder 自编码 AutoEncoder 是一种无监督学习的算法,他利用反向传播算法,让目标值等于输入值。 比如对于一个神经网络,输入一张图片,通过一个 Encoder 神经网络,输出一个比较 "浓缩的"feature map。之后将这个 feature map 通过一个 Decoder 网络,结果又将这张图片恢复。 如果说我们的数据集特别大,对于直接训练而言性能肯定较低。但如果我们对数据特征进行提取,缩减输入信息量,学习起来就相对轻松。 简单模型 下面是一个AutoEncoder的三层模型,其中 \(W^* = W^T\) 2010年,Vincent 在论文中表明,只用单组W就可以,所以W*没有必要去训练。 http://jmlr.org/papers/volume11/vincent10a/vincent10a.pdf 如果实数作为输入,损失函数为 \(L(f(x)) = {1\over2}\sum_{k}(\hat x_k - x_k)^2\) PCA 和...

2021-11-08
Sentiment Analysis For RNN
Sentiment Analysis For RNN 循环神经网络进行情感分析 引言: 对于情感分析,如果简化来看可以分为正向情绪和负向情绪,我们可以将情感分析视为文本分类任务,因此我们可以将预训练的词向量应用于情感分析。我们可以用预训练的GloVe模型表示每个标记,并反馈到RNN中。 RNN表征文本 在文本分类任务中,要将可变长度的文本序列转为固定长度。可以通过nn.Embedding()函数获得单独的预训练GloVe,再去通过双向LSTM,最后在去通过一个全连接层做一个二分类,即可实现RNN表征文本。 123self.embedding = nn.Embedding(vocab_size, embed_size)self.encoder = nn.LSTM(embed_size, num_hiddens, num_layers=num_layers,bidirectional=True)self.decoder = nn.Linear(4 * num_hiddens, 2) 1234embeddings =...

2021-11-24
Seq2Seq
Seq2Seq 以往的循环神经网络,输入的是不定长的序列,输出确是定长的,我们选取最长词并通过对短的词扩充来实现输出定长。但有些问题的输出不是定长的,以机器翻译为例,输入一段英语,输出对应法文,输入和输出大概率不定长,比如 英文:Beat it. 法文:Dégage ! 英文:Call me. 法文:Appelle-moi ! 当输入输出序列不定长时,我们可以采用编码器-解码器(encoder-decoder)或Seq2Seq实现。 论文参考:https://arxiv.org/abs/1409.3215 编码器-解码器 编码器和解码器分别对应输入序列和输出序列的两个循环神经网络。 编码器 编码器将长度可变的输入序列转换成形状固定的上下文变量,并且将输入序列的信息在该上下文变量中进行编码。 假设输入序列是\(x_1,x_2,x_3...x_T\) ,其中\(x_t\)是输入文本序列中第t个词原,用\(h_t\) 来表示上一时间的隐藏状态,用函数\(f\)来描述为 \[ h_t=f(x_t,h_t−1) \] 编码器的背景向量 \[ c =...

2021-12-08
朴素贝叶斯分类器
朴素贝叶斯分类器 完整代码:https://github.com/JiaZhengJingXianSheng/Naive-Bayes-Classify 基础 贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下,如何完成推理和决策任务。 而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特 征与其他特征都不相关。 朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习 的样本集中能获取得非常好的分类效果。 条件概率 假设A,B是两个随机变量,它们的联合概率 P(A=x,B=y) 是指 A=x和B=y同时 发生的概率。 如果A和B是两个随机变量,且 P(B)≠0 。那么B条件下,A 的条件概率为 \[ P(A|B)=\frac{P(A,B)}{P(B)} \] 我们用Ω代表总样本空间,P(A|B)的隐含假设是,B确定要发生。当确定B发生时, 样本空间不再是Ω,而是缩小成B。我们在B样本空间中 寻找A发生的概率。 贝叶斯定理 贝叶斯定理 (Bayes theorem)...




