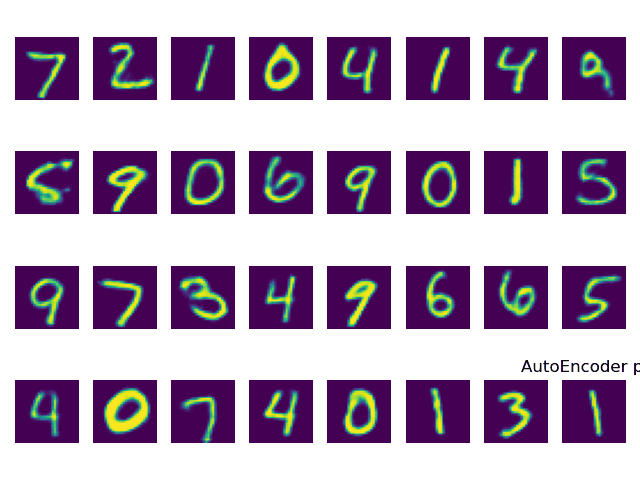AutoEncoder
AutoEncoder
自编码 AutoEncoder 是一种无监督学习的算法,他利用反向传播算法,让目标值等于输入值。
比如对于一个神经网络,输入一张图片,通过一个 Encoder 神经网络,输出一个比较 "浓缩的"feature map。之后将这个 feature map 通过一个 Decoder 网络,结果又将这张图片恢复。


如果说我们的数据集特别大,对于直接训练而言性能肯定较低。但如果我们对数据特征进行提取,缩减输入信息量,学习起来就相对轻松。
简单模型
下面是一个AutoEncoder的三层模型,其中 \(W^* = W^T\)
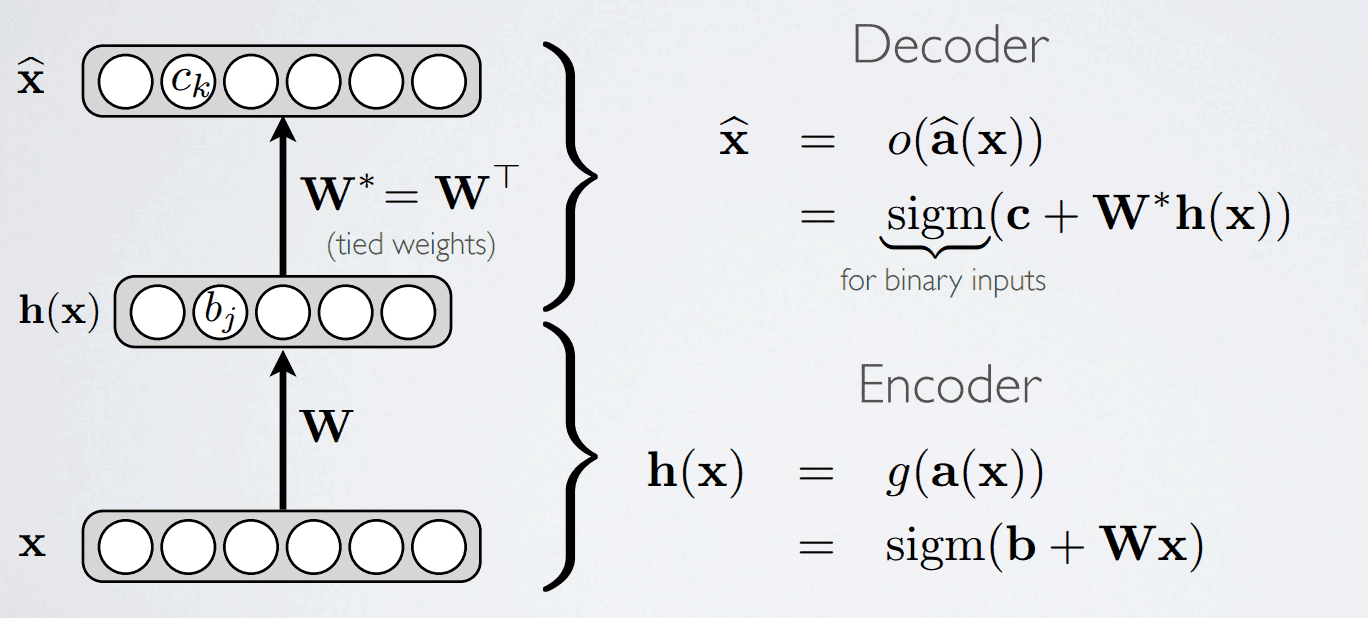
2010年,Vincent 在论文中表明,只用单组W就可以,所以W*没有必要去训练。
http://jmlr.org/papers/volume11/vincent10a/vincent10a.pdf
如果实数作为输入,损失函数为 \(L(f(x)) = {1\over2}\sum_{k}(\hat x_k - x_k)^2\)
PCA 和 AutoEncoder
PCA又叫主成分分析法,是将n维特征映射到k维上,本质上是个线性变化。而AutoEncoder是基于DNN的,因为有激活函数,所以可以进行非线性变换。下图是MNIST数据集经过 PCA 和AutoEncoder 降维再还原后的效果。

可以看到AutoEncoder效果是明显优于PCA。
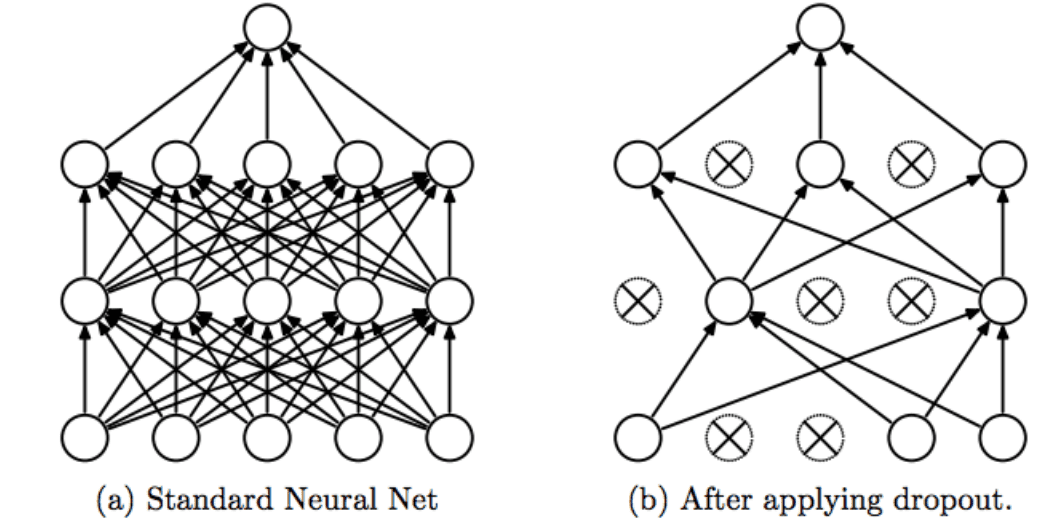
Dropout AutoEncoder
Dropout AutoEncoder是不断让神经元死亡以达到缩减特征的效果。
下图是一个简单的神经元图。
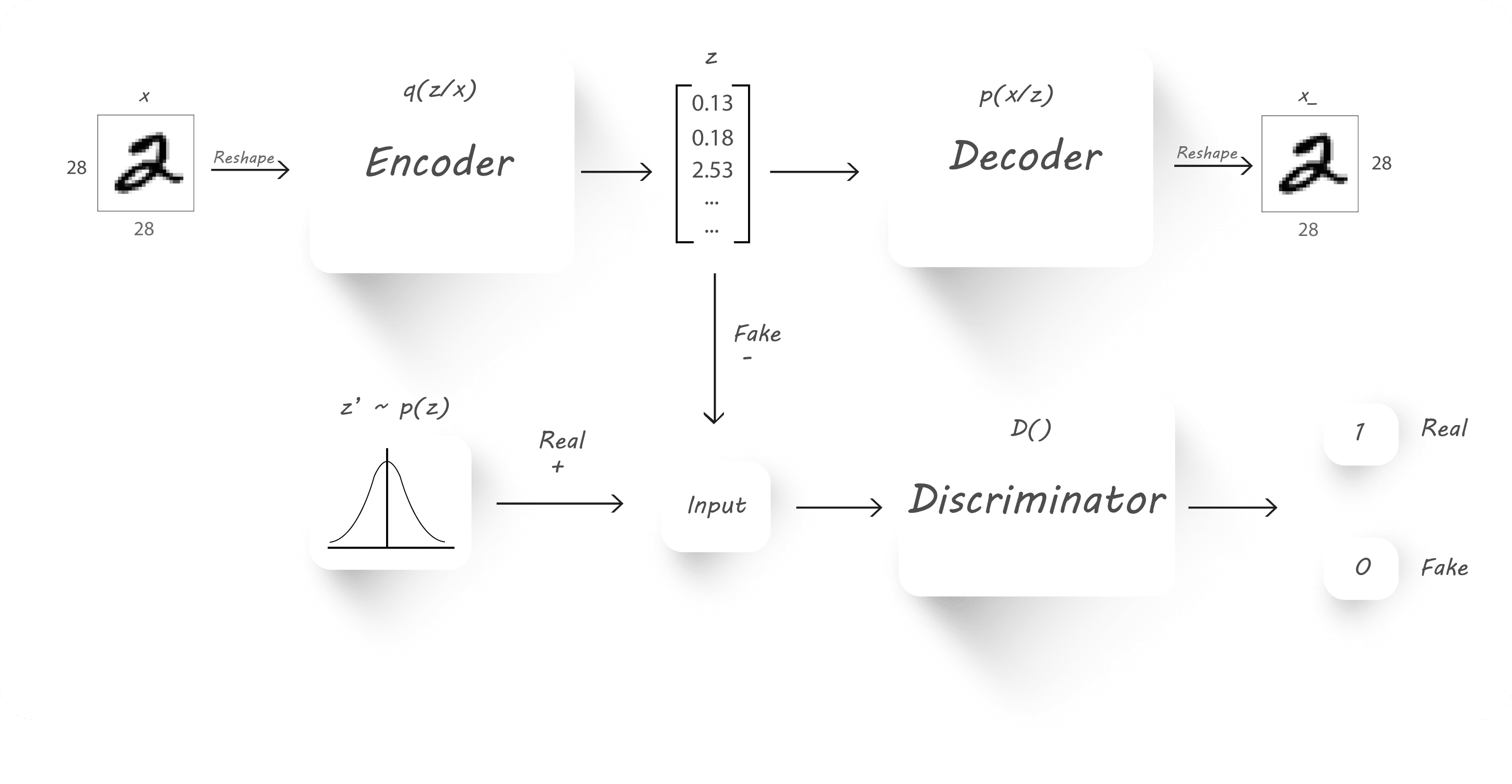
Adversarial AutoEncoders
Adversarial AutoEncoders是利用GAN网络的思想,利用一个生成器 G 和一个判别器 D 进行对抗学习,以区分 Real data 和 Fake data。
具体思路是这样的,我现在需要一个满足 p(z) 概率分布的 z 向量,但是 z 实际上满足 q(z) 分布。那么我就首先生成一个满足 p(z) 分布的 z′ 向量,打上 Real data 的标签,然后将 z 向量打上 Fake data 的标签,将它们俩送入判别器 D。判别器 D 通过不断学习,预测输入 input 是来自于 Real data(服从预定义的 p(z) 分布)还是 Fake data(服从 q(z) 分布)。由于这里的 p(z) 可以是我们定义的任何一个概率分布,因此整个对抗学习的过程实际上可以认为是通过调整 Encoder 不断让其产生数据的概率分布 q(z) 接近我们预定义的 p(z)。
AutoEncoder代码实现
https://github.com/JiaZhengJingXianSheng/AutoEncoder
结果分析
下面这张图是原本mnist数据集的图。
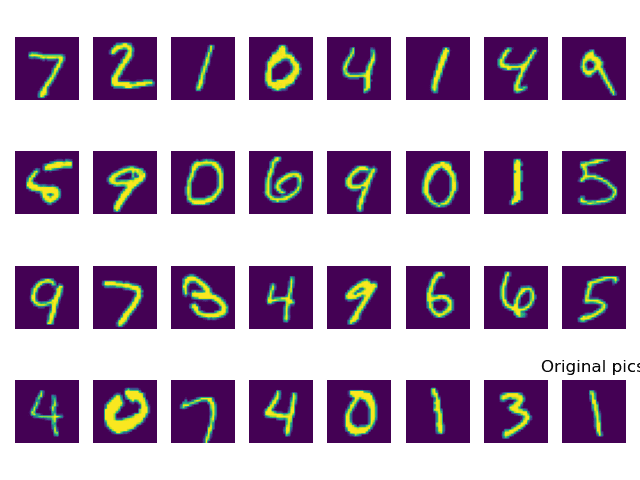
在epochs = 1 情况下,在经过编码器编码,解码器恢复的结果为下图。
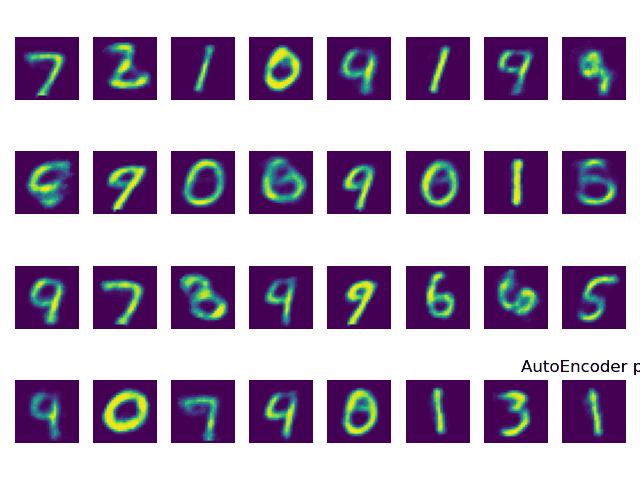
因为DNN是有损失的,所以在恢复的过程中肯定是有部分信息丢失。但可以通过训练次数的提升,来减少信息丢失,下图为epochs = 50 情况下恢复出来的结果,可以看到效果明显优于上图。