Seq2Seq
Seq2Seq
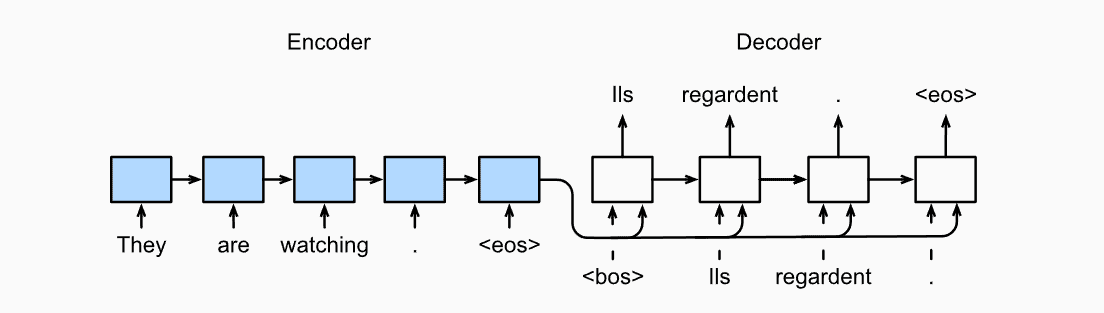
以往的循环神经网络,输入的是不定长的序列,输出确是定长的,我们选取最长词并通过对短的词扩充来实现输出定长。但有些问题的输出不是定长的,以机器翻译为例,输入一段英语,输出对应法文,输入和输出大概率不定长,比如
英文:Beat it. 法文:Dégage ! 英文:Call me. 法文:Appelle-moi !
当输入输出序列不定长时,我们可以采用编码器-解码器(encoder-decoder)或Seq2Seq实现。
论文参考:https://arxiv.org/abs/1409.3215
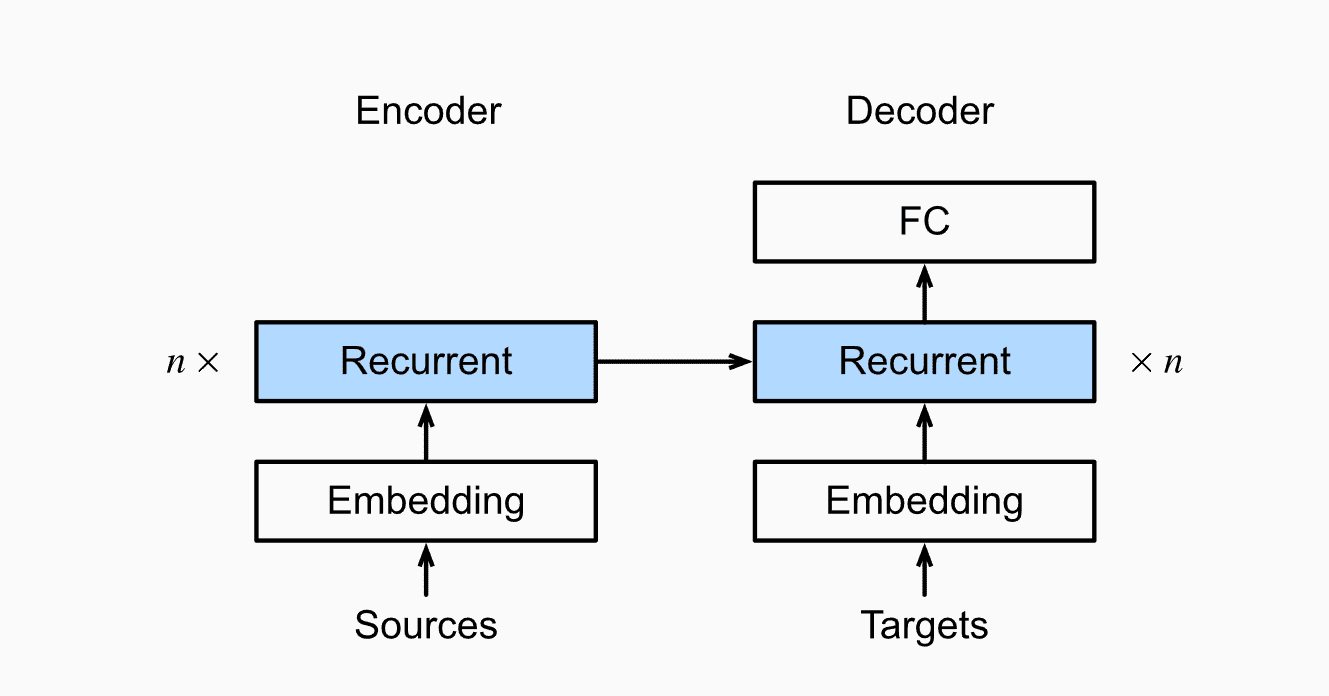
编码器-解码器
编码器和解码器分别对应输入序列和输出序列的两个循环神经网络。
编码器
编码器将长度可变的输入序列转换成形状固定的上下文变量,并且将输入序列的信息在该上下文变量中进行编码。
假设输入序列是\(x_1,x_2,x_3...x_T\) ,其中\(x_t\)是输入文本序列中第t个词原,用\(h_t\) 来表示上一时间的隐藏状态,用函数\(f\)来描述为 \[ h_t=f(x_t,h_t−1) \] 编码器的背景向量 \[ c = q(h_1,...,h_T) \] 如果我们希望编码器既包含正向传递的信息,又包含反向传递的信息,可以使用双向循环神经网络。
解码器
通过编码器,假定我们的输入序列为 \(x_1,x_2,...,x_T\) 。输出序列为\(y_1,y_2,...,y_T\) ,我们希望每个时刻的输出向量,既取决于之前的输出又取决于背景向量。所以我们可以用循环神经网络\(g\) 来实现,其中\(s_t\) 为\(t'\) 世界的解码器隐藏变量,该隐藏变量为 \(s_{t'} = g(y_{t'-1},c,s_{t'-1})\) 一般编码器和解码器会使用多层循环神经网络。
实现
通常我们会在解码器后面增加一个FC,并且现在我们实现中一般采用嵌入层(Embedding)来获得输入序列中每个词元的特征向量。